Oracle-DB: How to enforce the optimizer to do group operations at the most inner level
The most efficient way of processing GROUP BY or SORT operations is often if they are executed only at the really necessary DB objects and the smallest number of rows and columns.
Disadvantage:
Disadvantage:

Disadvantage:

Disadvantage:

Disadvantage:

The optimizer itself tends to move GROUP BY and SORT operations out to the last operation of a SQL, thus executing these operations on larger data sets than necessary.
One way to improve that is to use the so called VIEW_PUSHED_PREDICATE feature forced by the NO_MERGE hint.
Prepare example task
You have two tables ORDER and POSITION.CREATE TABLE Orders (
ID NUMBER,
Customer_ID NUMBER,
CreationDate DATE
);
INSERT INTO Orders
SELECT Level, dbms_random.random, SYSDATE - Level/10000.0
FROM DUAL
CONNECT BY Level <= 1000000
;
COMMIT;
ALTER TABLE Orders ADD CONSTRAINT Orders_PK PRIMARY KEY (ID);
CREATE INDEX Order_Customer ON Orders(Customer_ID);
EXEC DBMS_Stats.Gather_Table_Stats(SYS_CONTEXT('USERENV', 'SESSION_USER'), 'ORDERS');
CREATE TABLE Positions (
Order_ID NUMBER,
Quantity NUMBER,
Price NUMBER
);
INSERT INTO Positions
SELECT ID, 23, 27.3 FROM Orders
UNION ALL
SELECT ID, 17, 12.2 FROM Orders
UNION ALL
SELECT ID, 4, 8.43 FROM Orders
;
CREATE INDEX Position_Order ON Positions(Order_ID);
EXEC DBMS_Stats.Gather_Table_Stats(SYS_CONTEXT('USERENV', 'SESSION_USER'), 'POSITIONS');
Now you should select the orders of a customer, enriched with the sum of price and quantity from positions. The result should contain one row per order.
To check the runtime of the selects loop through all orders after warmup of DB cache like here for the first variant (Note the NO_MERGE hint to ensure that the SQL is really executed):
DECLARE
Dummy NUMBER;
BEGIN
FOR Rec IN (SELECT Customer_ID FROM Orders) LOOP
SELECT COUNT(*) INTO Dummy FROM (
SELECT /*+ NO_MERGE */ o.ID, MIN(o.CreationDate) CreationDate,
SUM(p.Quantity) Quantity, SUM(p.Price) Price
FROM Orders o
JOIN Positions p ON p.Order_ID = o.ID
WHERE o.Customer_ID = Rec.customer_id
GROUP BY o.ID
);
END LOOP;
END;
/
The shown execution plan is always the plan of the test run with surrounding SELECT COUNT(*) including this SQL as subselect with NO_MERGE hint. Tested at Oracle release 19.19.
Inefficient real life solutions
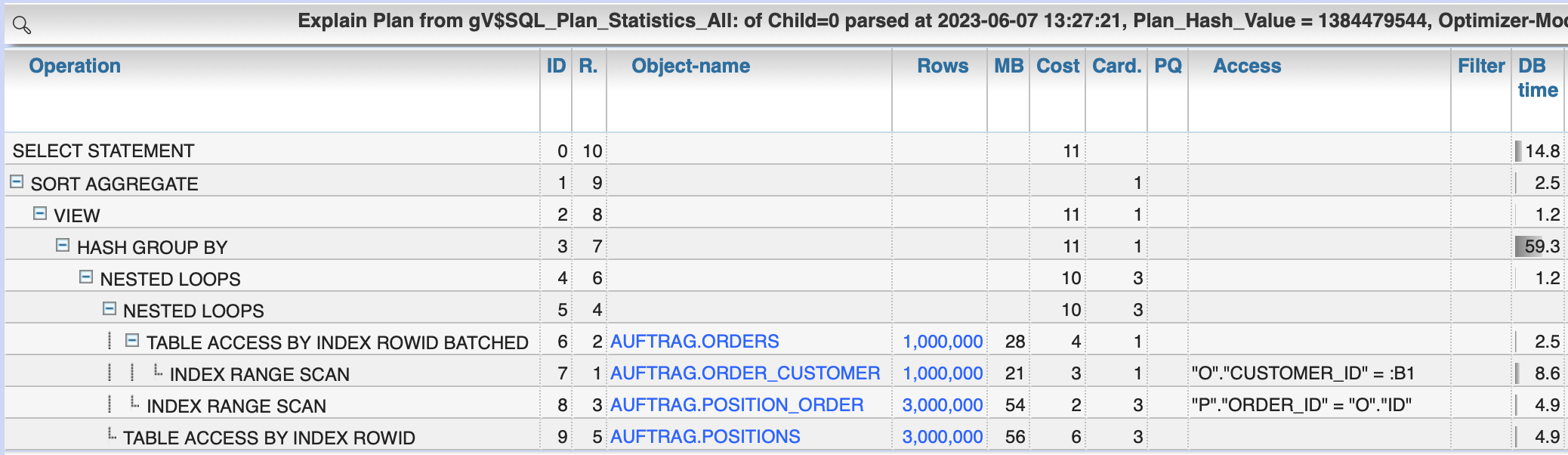
You may find different solutions that get the expected result but with not that efficient as would be possible.Variant 1: Join the tables, temporary result with number of positions, then GROUP BY to reduce to orders
SELECT o.ID, MIN(o.CreationDate) CreationDate,
SUM(p.Quantity) Quantity, SUM(p.Price) Price
FROM Orders o
JOIN Positions p ON p.Order_ID = o.ID
WHERE o.Customer_ID = :customer_id
GROUP BY o.ID
;
Execution plan:
Disadvantage:
- You need fake aggregate functions for additional ORDER columns or you need to place them in the GROUP BY clause
- You need to group the whole result of ORDER and POSITIONS for that customer
Variant 2: Use susbselects in select list
SELECT o.ID, o.CreationDate,
(SELECT SUM(p.Quantity) FROM Positions p WHERE p.Order_ID = o.ID) Quantity,
(SELECT SUM(p.Price) FROM Positions p WHERE p.Order_ID = o.ID) Price
FROM Orders o
WHERE o.Customer_ID = :customer_id
;
Execution plan:
Disadvantage:
- The optimizer may detect the redundancy and use a global GROUP BY at the most outer level comparable to variant 1
- If not it uses a plan similar to variant 2b
Variant 2b: Use NO_MERGE hint to force the optimizer to GROUP/SORT at inner select
This forces the optimizer to do the selects on POSITION as atomic operations after getting the result from table ORDER.SELECT o.ID, o.CreationDate,
(SELECT /*+ NO_MERGE */ SUM(p.Quantity) FROM Positions p WHERE p.Order_ID = o.ID) Quantity,
(SELECT /*+ NO_MERGE */ SUM(p.Price) FROM Positions p WHERE p.Order_ID = o.ID) Price
FROM Orders o
WHERE o.Customer_ID = :customer_id
;
Execution plan:
Disadvantage:
- The table POSITION is attached twice
- The atomic GROUP/SORT operation on POSITION is executed twice
Variant 3: Use subselect in JOIN with additional access on ORDER
SELECT o.ID, o.CreationDate, p.Quantity, p.Price
FROM Orders o
JOIN (SELECT o2.ID Order_ID, SUM(p.Quantity) Quantity, SUM(p.Price) Price
FROM Orders o2
JOIN Positions p ON p.Order_ID = o2.ID
GROUP BY o2.ID
) p ON p.Order_ID = o.ID
WHERE o.Customer_ID = :customer_id
;
Execution plan (optimizer eliminated the redudant table access in this case) :
Disadvantage:
- Additional inner access on ORDER is redundant
- GROUP operation may be moved to the most outer level of the SQL
Variant 3b: Double the filter on Customer_ID in the inner subselect
SELECT o.ID, o.CreationDate, p.Quantity, p.Price
FROM Orders o
JOIN (SELECT o2.ID Order_ID, SUM(p.Quantity) Quantity, SUM(p.Price) Price
FROM Orders o2
JOIN Positions p ON p.Order_ID = o2.ID
WHERE o2.Customer_ID = :customer_id
GROUP BY o2.ID
) p ON p.Order_ID = o.ID
WHERE o.Customer_ID = :customer_id
;
Execution plan (optimizer eliminated the redudant index access in this case using adaptive plans) :
Disadvantage:
- The same like Variant 3
- Index on Customer_ID is accessed twice
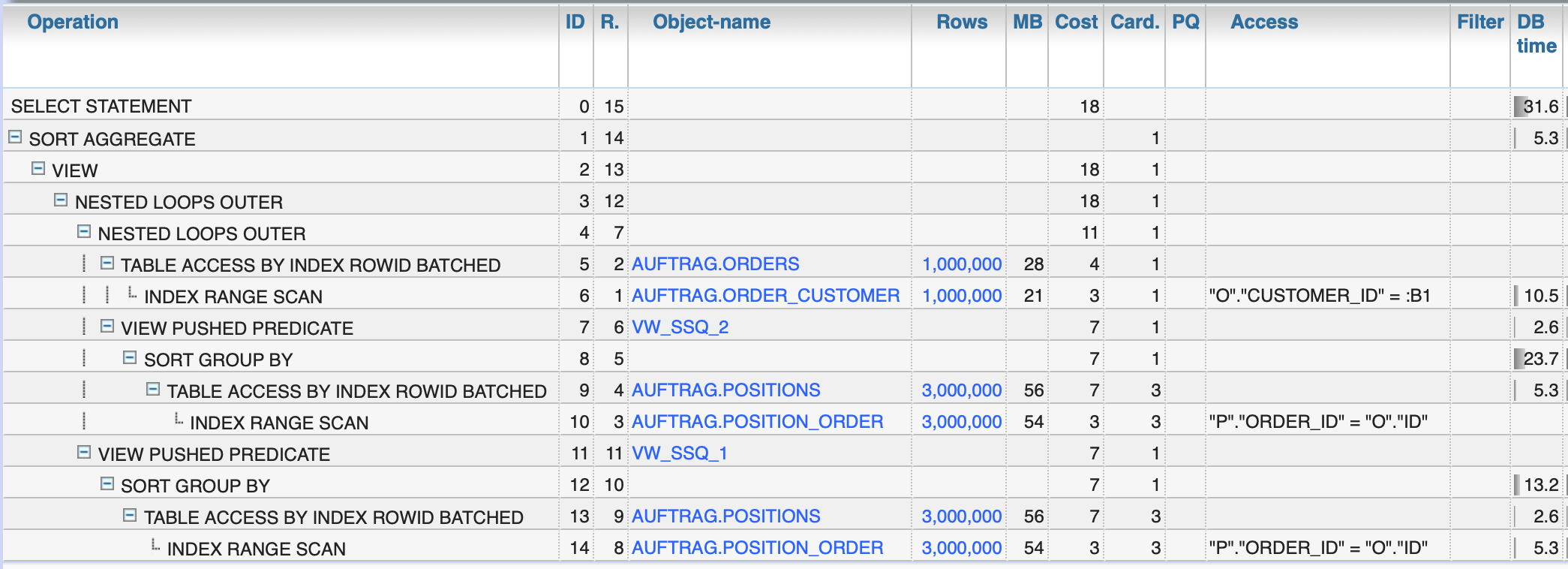
Suggested solution using VIEW_PUSHED_PREDICATES
SELECT o.ID, o.CreationDate, p.Quantity, p.Price
FROM Orders o
JOIN (SELECT /*+ NO_MERGE */ Order_ID, SUM(Quantity) Quantity, SUM(Price) Price
FROM Positions
GROUP BY Order_ID
) p ON p.Order_ID = o.ID
WHERE o.Customer_ID = :customer_id
;
Execution plan:
- Both tables are accessed only once
- The GROUP/SORT operation is done only at the result from POSITION for one Order_ID
- The optimizer costs often don’t rate this solution as best one, therefore the NO_MERGE hint forces to use the VIEW_PUSHED_PREDICATE operation
In this example the benefit is 38% less runtime compared to the best alternative.
In reality, the benefit is often significantly greater due to a larger number of columns and more joined data sources.
Additional benefit of suggested solution
Also if additional sub results / filtered results are needed from POSITIONS they can be gotten without additional subselects etc. from the same selection on POSITIONS. Example: Get the sum of prices for positions with quantity = 1SELECT o.ID, o.CreationDate, p.Quantity), p.Price, p.Price1
FROM Orders o
JOIN (SELECT /+ NO_MERGE */ Order_ID, SUM(Quantity) Quantity, SUM(Price) Price,
SUM(CASE WHEN Quantity = 1 THEN Price END) Price1
FROM Positions
GROUP BY Order_ID
) p ON p.Order_ID = o.ID
WHERE o.Customer_ID = :customer_id
;
The execution plans are rendered with Panorama


Comments
Post a Comment