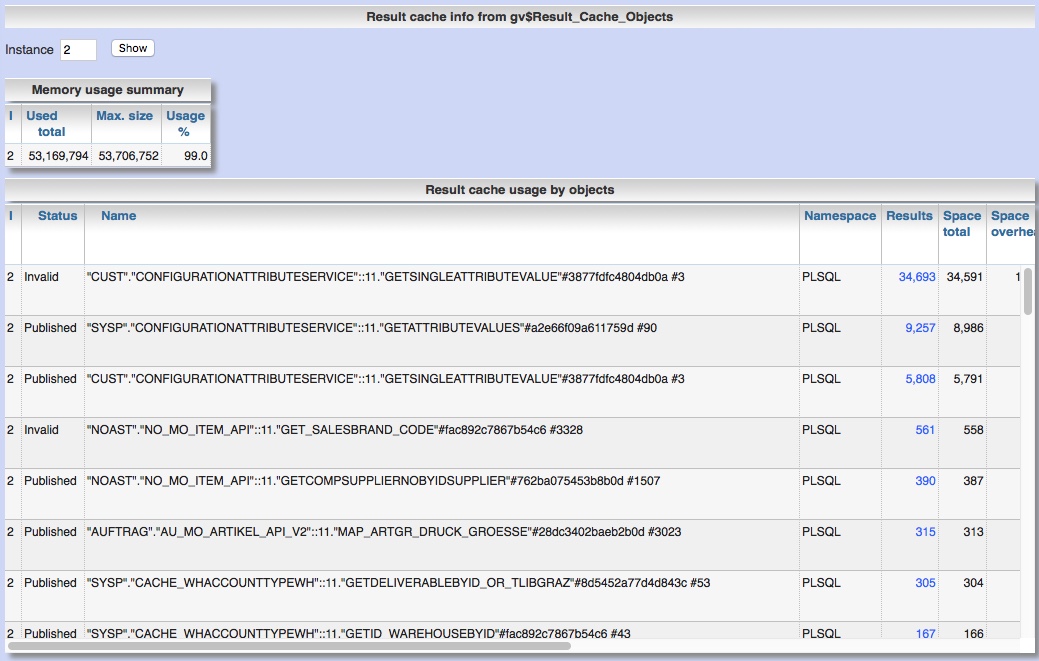
Analyze pluggable database with Panorama
Panorama now supports analysis of pluggable databases (PDB) too. Visibility of informations in CDB and PDB There are different informations visible wether you are selecting from DBA_xx-views or CDB_xx-views and your are connected to CDB or PDB Role / user connected Container-DB (CDB / root) Pluggable database (PDB) Kind of views CDB_xx DBA_xx CDB_xx DBA_xx system all PDBs including root all PDBs including root nothing your current PDB user (SELECT ANY DICTIONARY) all PDBs including root root CDB nothing your current PDB Posted on "Analyze pluggable database with Panorama"