Panorama: How to identify and evaluate SQL with different execution plans
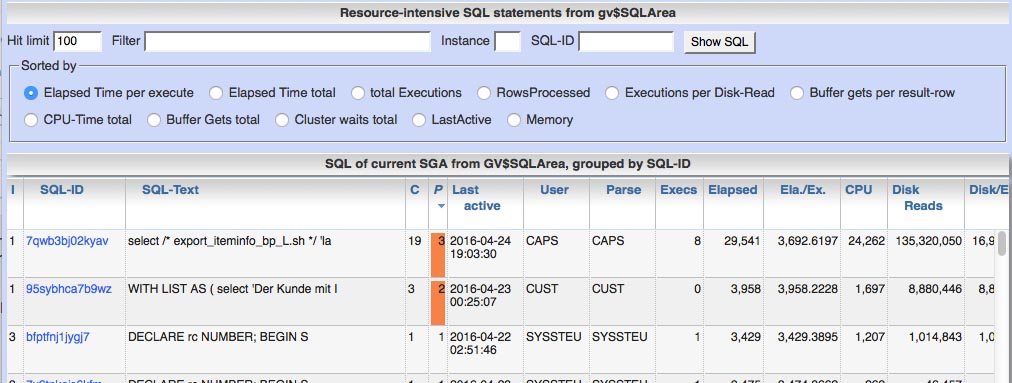
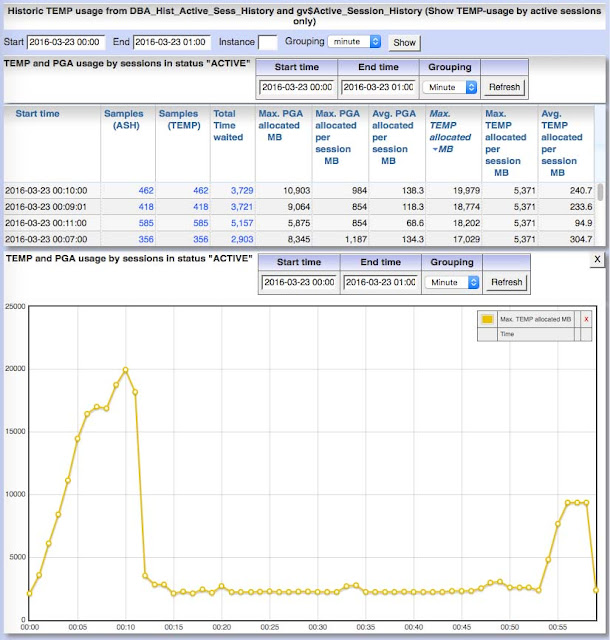
How to identify changing execution plans in Panorama Changing or alternating executions plans often contains the risk of unpredictable runtime for SQL-statements. There are several ways in Panorama to find SQL statements with different execution plans: 1. Lookup into current SGA: If you list SQLs from SGA (Menu „SGA/PGA details“ / „SQL-Area“ / „Current (SQL-ID)“), there’s the fifth column „P.“ in the table which shows the number of different plans in SGA for a SQL-statement (orange background if more than one plan occurred). 2. Lookup into SQL history: If you list historic SQLs from AWR history (Menu „SGA/PGA details“ / „SQL-Area“ / „historic“), there’s also a column „P.“ in the table which shows the number of different plans within the choosen period for a SQL-statement. 3. SQL details page for period in history At the SQL details page you find the number of different execution plans in the considered period at the right upper corner. 4. Complete time line of SQ...