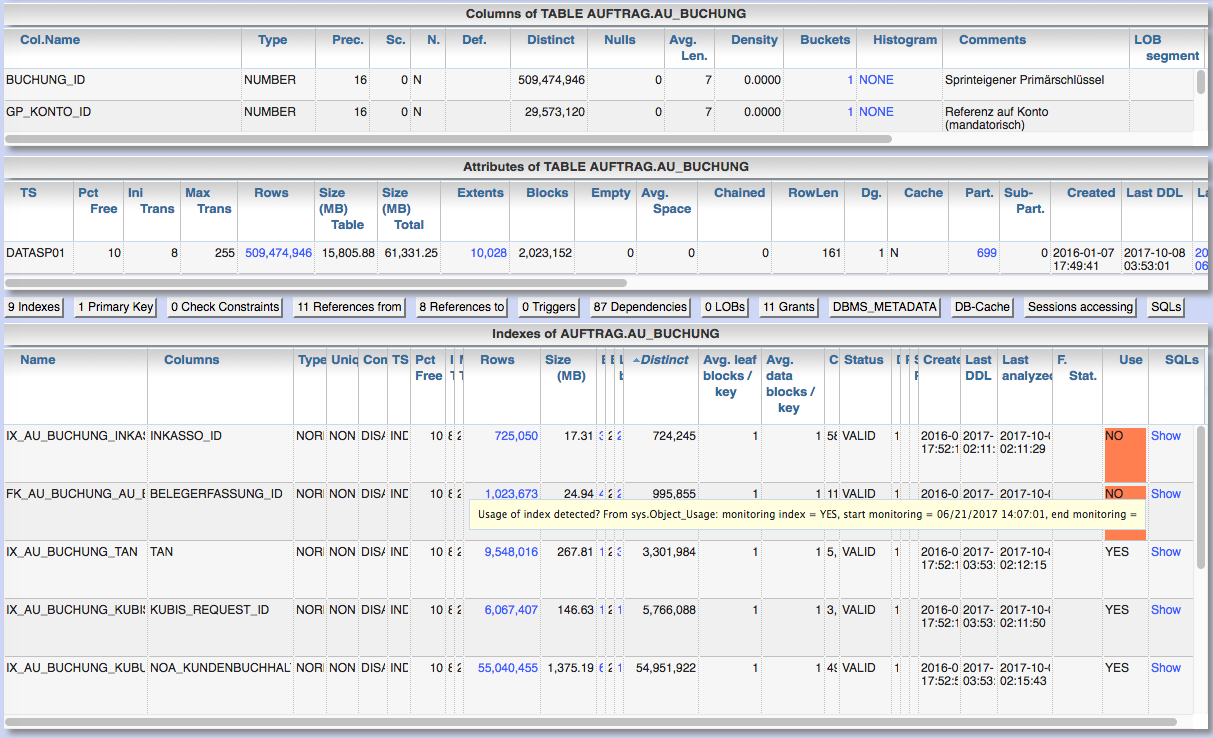
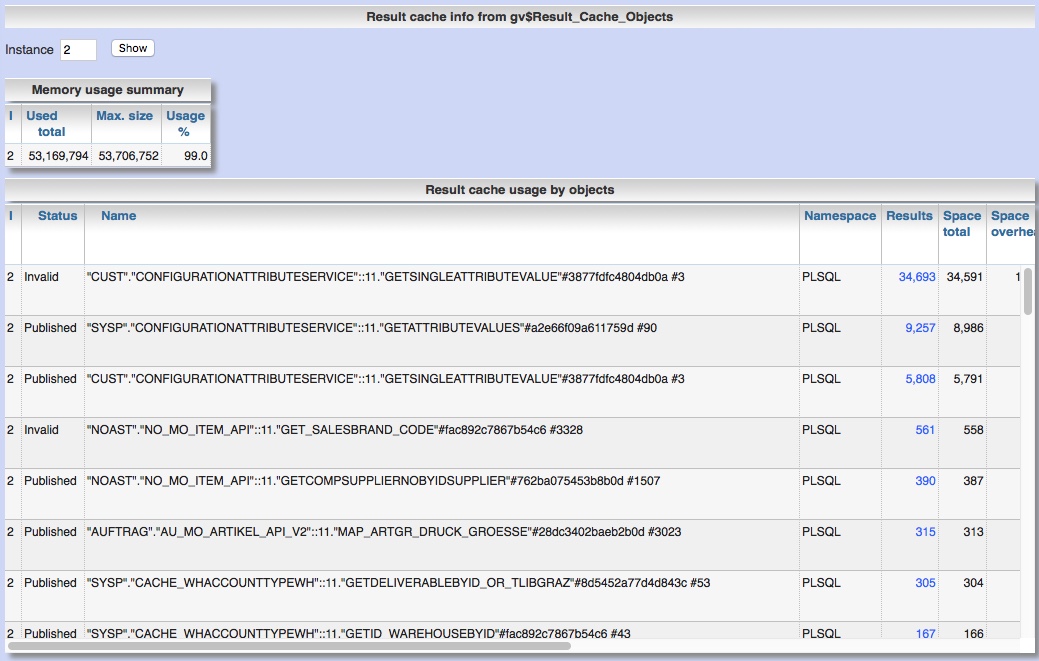
Panorama: Handle SQL patches for Oracle-DB

Long time ago Oracle introduced SQL patches as a way to influence execution plan of SQL with optimizer hints without changing the original SQL statement. This allows fixing execution plan issues without any change at the application executing this SQL. SQL patches don't require additional license in contrast to SQL plan baselines and SQL profiles and can also be used with Standard Edition. SQL patches are normally used in workflow of SQL Repair Advisor but can also be created manually. There are two variants to create a SQL patch for a SQL: By SQL-ID and by SQL text. (See also this posts: 1 2 ) I personally prefer SQL patch creation using SQL text because SQL-ID requires existence of SQL-Statement in SGA at SQL patch creation time. For Oracle 11.1 .. 12.1 create with package-method sys.DBMS_SQLDiag_Internal.i_create_patch BEGIN sys.DBMS_SQLDiag_Internal.i_create_patch( sql_text => 'SELECT SYSDATE FROM DUAL', hint_text => 'PARALLEL(8)...