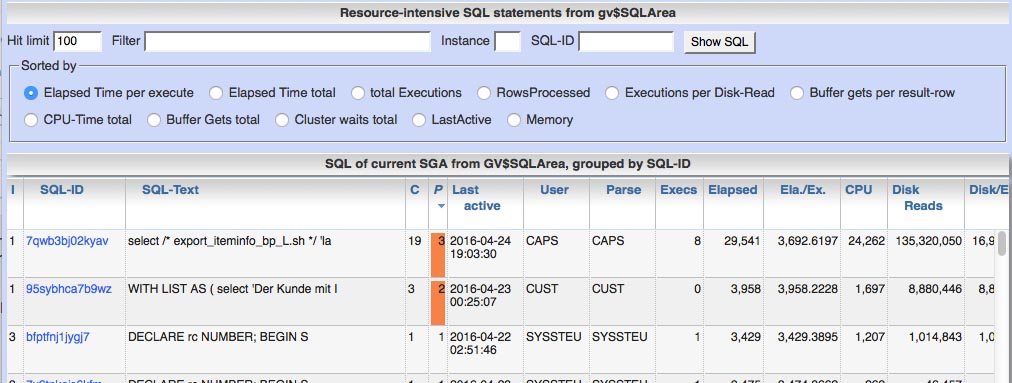
Generate recommendation lists for index compression on Oracle-DB

An often underrated feature of Oracle databases since version 9i is key compression for indexes . It allows reduction of index footprint until 1/2 of uncompressed size depending from key size and number of rows per key. Compressing an index is quite simple: ALTER INDEX MyIndex REBUILD COMPRESS; to compress all keys of an index or ALTER INDEX MyIndex REBUILD COMPRESS 2 to compress only the first two columns of an multicolumn index. But how to determine which indexes of an existing database system are worth compressing? You can generate weighted recommendation lists for index compression by executing the following SQL statements at your database with an user who has the grant SELECT ANY DICTIONARY. Version 1: Rate indexes by selectivity SELECT * FROM ( SELECT ROUND(i.Num_Rows/i.Distinct_Keys) Rows_Per_Key, i.Num_Rows, i.Owner, i.Index_Name, i.Index_Type, i.Table_Owner, i.Table_Name, t.IOT_Type, ( SELECT ROUND(SUM(bytes)...