Common Oracle DB pitfall: too few redo log groups

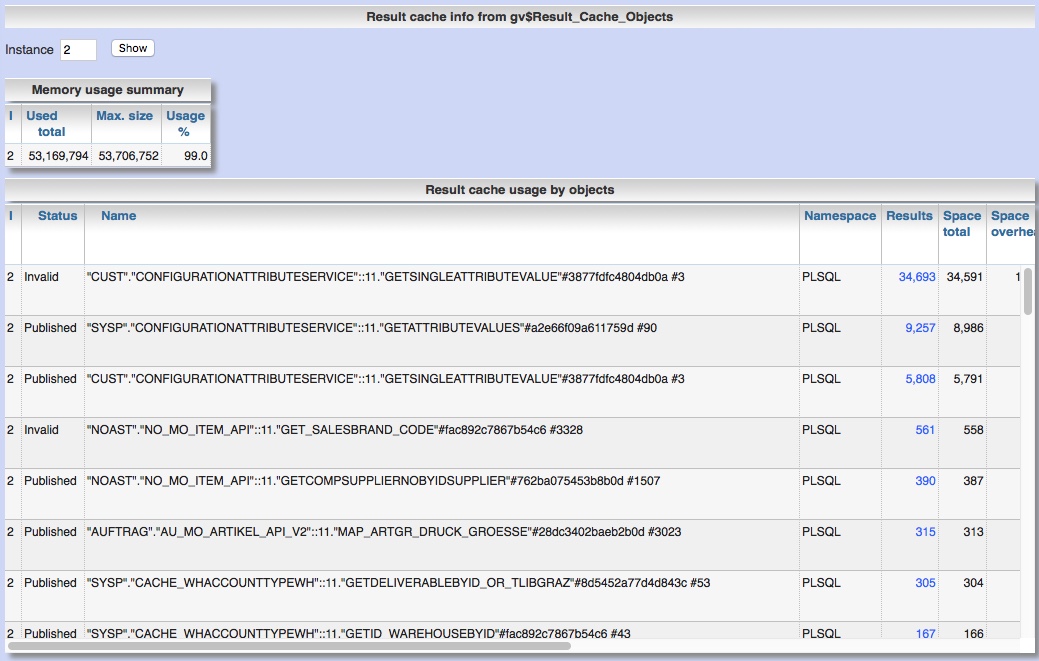
Running an Oracle database with only 3 redo log groups often leads to suddenly frozen database, there all commit operations are suspended for some seconds or even some minutes. This freeze behavior may cause several errors in production environments: Services are not available, timeout exceptions are raised, process throughput decreases considerably etc. . Unfortunately only 3 redo log groups is the default for a database created by DBCA and therefore you may find many DB instances in production with only 3 redo log groups. But why should it be a problem to have too less redo log groups? For example we have a database with 3 redo log groups and as advisable for production databases, archiver mode is activated. Consider the redo logs as ring buffer where a fix number of redo log file groups is reused by the log writer process after the current log is completely written and a log switch is raised. The precondition for successful log switch is that the next log file group to s...