Oracle-DB: Does Active Session History always allows you to reconstruct your active sessions behaviour?

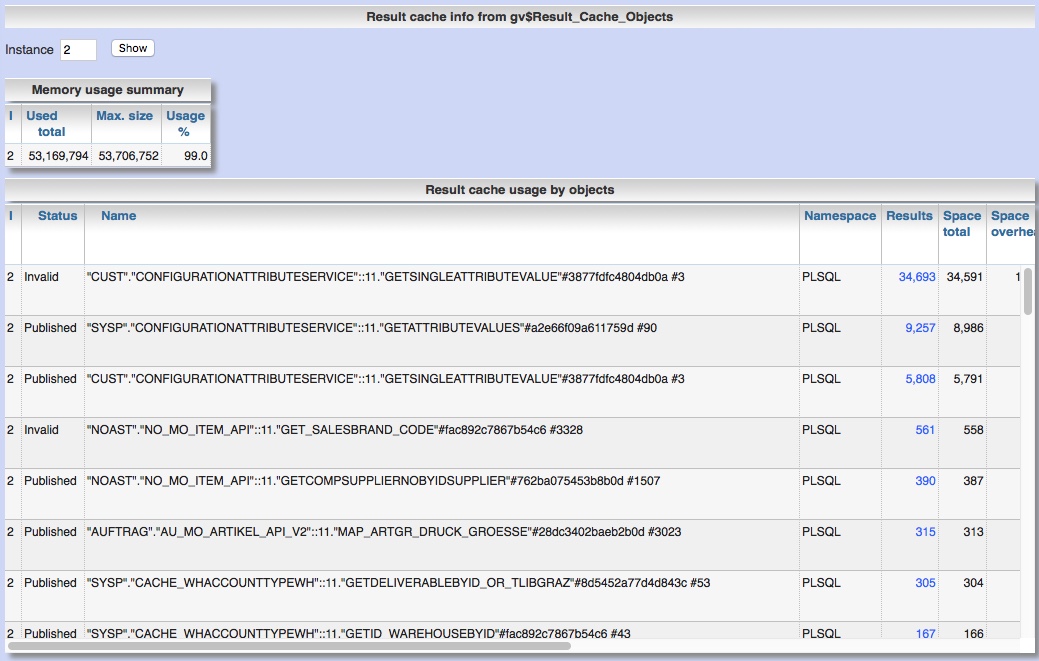
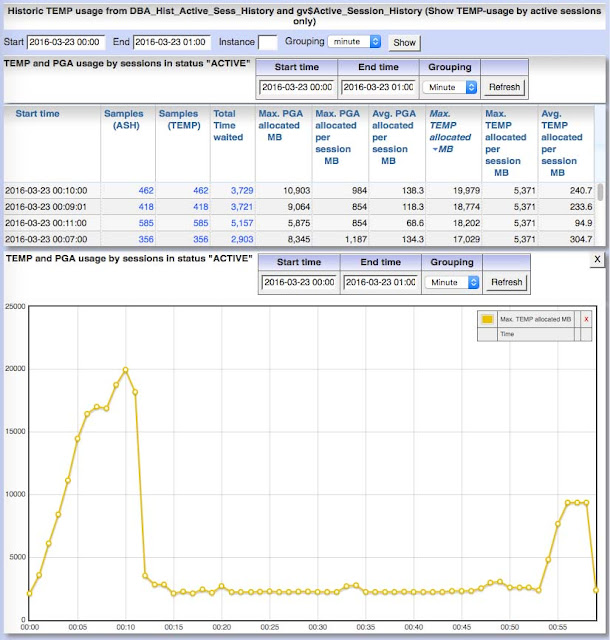
As the name implies one would expect that Active Session History records all information to reconstruct the main activities of sessions that are active for a longer period. Is it really true? I thought so before, but it isn't. Consider the ASH-chart of this session running for approx. one hour as one unique PL/SQL package-method call. What you would expect is that over this time the session is always active doing PL/SQL- or SQL-execution work. That means this session is permanently active and wait states should be recorded in ASH. But ASH-report says that this session is mostly inactive consuming time but doing nothing on database. The reason for this confusion is: Active Session History does not record wait states for wait class "idle". In this special case the idle waits are caused by one frequently executed SQL-statement accidentially forced to run in parallel query mode by a PARALLEL-hint, but each SQL-execution took only some milliseconds. If you ...