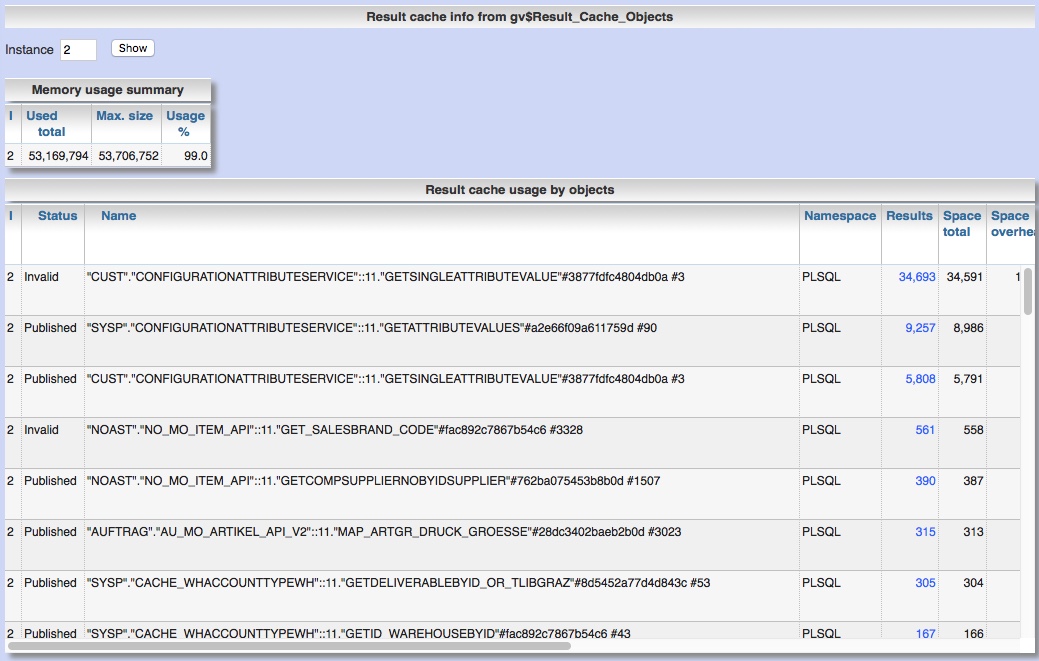
Panorama: Explore free space fragmentation of tablespaces

Unfortunately the number of free bytes in your tablespaces does not really ensure that you are still able to allocate new extents in tablespace. Except you have choosen UNIFORM EXTENT SIZE as allocation type, than your free space chunks may not be smaller than your uniform extent size and you can skip here. To allocate a new extent on one of your tablespace's objects you must ensure that there is an existing contiguous chunk of free space that your extent may totally fit in. With Panorama you are enabled to explore with one click the fragmentation of your tablespace and remaining space for different extent sizes. There may be a remaining question: With what size will the next extent be created for my table or index to estimate wether it will fit in free space? You can recognize this by exploration of the existing extents of your object and the assumption that the next extent will be created with: the size of the largest existing extent for SYSTEM allocation t...